
点击上方蓝字关注我们

基于法律裁判文书的法律判决预测
张虎1, 潘邦泽1, 谭红叶1, 李茹1,2
1 山西大学计算机与信息技术学院,山西 太原 030006
2 山西大学计算智能与中文信息处理教育部重点实验室,山西 太原 030006
摘要:针对智慧司法服务领域中“法律判决预测”任务的实际需求,探讨了法律判决预测任务的研究思路与实现路径,介绍了法律判决预测的整体框架和具体过程。基于从中国裁判文书网获取的海量真实案件数据和2018“中国法研杯”司法人工智能挑战赛的评测数据,整理了实验数据类别,规范了实验数据格式,形成了基于法律裁判文书大数据的法律判决预测数据集。在判决预测模型中,首先使用判决要素抽取方法提取出高质量的判决要素句,然后借鉴法官的判案思路,将整个法律判决预测任务转换为法条预测、罪名预测和刑期预测3项子任务,并分别构建了基于判决要素的预测模型。实验结果表明,所提方法在刑法类判决预测数据集上得到了有效的结果。
关键词:法律判决预测 ; 判决要素抽取 ; 法条预测 ; 罪名预测 ; 刑期预测

论文引用格式:
张虎, 潘邦泽, 谭红叶, 等. 基于法律裁判文书的法律判决预测. 大数据[J], 2021, 7(5):164-175.
ZHANG H, PAN B Z, TAN H Y, et al. Legal judgment prediction based on legal judgment documents. Bigdataresearch[J],2021,7(5):164-175.
1 引言
在人工智能与大数据技术的推动下,从2013年起,我国各级司法机构就进入了以提供智能司法服务为目的的“智慧司法”建设时期。在2014年与2016年,最高人民法院相继推出了人民法院数据集中管理平台与国家司法审判系统,并开通了中国裁判文书网与中国法律应用数字网络服务平台。2017年7月,国家人工智能战略《新一代人工智能发展规划》对人工智能理论、技术和应用做出前瞻布局,呼吁加强人工智能相关法律、伦理和社会问题研究。同时,该规划力挺智慧法庭建设,提出促进人工智能在证据收集、案例分析、法律文件阅读与分析中的应用。
在同一时期,大数据与人工智能技术在各行各业都引起了高度的重视,并得到了广泛的应用,人工智能在司法领域的应用已经成为未来法律工作中必不可少的一部分。无论是法官、律师还是普通大众,都会享受到智慧司法服务带来的便捷。智慧司法的主要思想是将人工智能技术,特别是自然语言处理(natural language processing,NLP)技术应用于法律领域的任务。一方面,智慧司法可以为不熟悉法律术语和复杂判决程序的群众提供低成本、高质量的法律咨询服务;另一方面,它可以为专业人士(如律师和法官)提供参考,将法律专业人士从错综复杂的文书工作中解放出来,提高他们的工作效率。同时,利用人工智能技术提升法律服务水平的思想也将被进一步普及,人们对正义与法律的理解将会被重新塑造,国家利用人工智能技术提升法律服务水平的目标也将被实现。
法律判决预测是“智慧司法”服务体系下的一项重要研究任务,在学术界和企业界受到广泛关注。其任务的核心目标是通过分析案件的相关信息,自动预测出案件最终的判决结果。然而,对于如何完成法律判决预测任务这一问题,面临着如下几个关键的挑战。
● 法律判决预测任务的研究要求使用真实的法律案件数据集,而真实法律案件信息的获取渠道较为广泛,且数据形式与包含内容各不相同。因此,统一各类数据的数据格式、构建高质量的数据集是法律判决预测任务的首要任务。
● 以往的判决预测大多将整篇法律文书作为输入。但在人类法官审理案件的过程中,判决结果往往仅由案件的核心描述决定,法律文书中的大多数内容对案件的判决结果影响较小,且大量无关内容还会直接影响最终的判决预测结果。因此,探索判决要素抽取方法对提升法律判决预测结果具有重要的意义。
● 法律判决预测任务要求提出的方法可以高质量地预测出案件的判决结果。然而,案件的判决结果同时包含了案件的法律条文(以下简称法条)、罪名、刑期等多种内容,大多数传统模型无法同时预测出多种信息。因此,如何使预测模型高质量地预测出完整的案件判决结果是法律判决预测任务的重要难点。
本文针对这些关键性问题,使用从中国裁判文书网获取的海量真实案件数据和2018“中国法研杯”司法人工智能挑战赛的评测数据构建实验数据集,结合人类法官的判决思路,探究基于法律裁判文书大数据的法律判决预测流程与方法。首先从事实描述中抽取判决要素句,然后针对法律判决预测中的法条预测、罪名预测和刑期预测任务分别训练独立的预测模型,最后结合所有子任务的结果形成案件的判决预测结果,具体案例如图1所示。
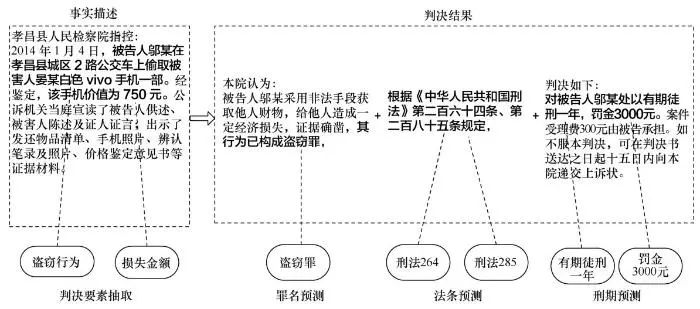
图1 判决预测具体案例
2 相关工作
在20世纪中叶,如何自动获得司法判决结果引起了法学界研究者的关注。这一时期的研究主要是在具体的场景下,运用数学和统计算法对现有法律案例进行分析。Kort F运用经典统计算法对司法数据进行分析,使用经典数学模型预测了最高法院的判决结果,并对“律师维权”案件进行了定量分析。Nagel S在分析大量法律文件后提出了“法律变量”的概念,从而达到为法官服务、帮助公众更方便地获得法律援助的目的。Ulmer S S使用规则的方法分析了大量的法律案件,协助法官对案件证据的梳理工作。Ringquist E J针对环境类的民事诉讼案,对司法判决做了深入的研究。Lauderdale B E等人最早使用各类法律案件数据的相似信息来研究不同种类法律案件的相似性。上述研究都需要从法律文书与法律案件概要中人工提取出关键特征。这一阶段开展的研究不仅需要大量的法律专业型人力参与完成,并且对不同种类法律案件的泛化能力也相对较差。
近年来,受到神经网络可以有效应用于NLP任务的启发,诸多学者针对法律判决预测任务展开了相关研究。Luo B F等人提出了基于注意力的神经网络,并在统一的框架中对罪名预测任务与案件相关法条进行联合训练,有效提升了罪名预测任务的效果。Jiang X等人提出了基于基本原理的增广分类模型,有效提升了罪名预测的精度。Chen H J等人针对被告往往被控多项罪行的问题,提出了一种基于罪名特定特征选择和聚集的深度门控网络,有效提升了刑期预测的精度,为刑期预测提供了可解释性。Hu Z K等人总结出10种法律判别属性,有助于提高针对易混淆法律案件的预测任务的准确率。Zhang H等人提出了数据离散化的方法,针对性地解决了普通模型对金额、年龄等数字类信息关注度较低的问题,进一步提升了法条预测模型的性能。Long S B等人分析了事实、请求与法律之间的语义交互关系,对事实描述、原告请求与法律条款之间的语义关系进行建模,进一步提升了判决预测的准确性。Yang W M等人发现判决预测的子任务间往往会忽略词语的搭配信息,并就此问题设计了具有词语搭配的注意力机制,提出了一种基于子任务间拓扑结构的多视角双反馈网络。Yang Z等人提出了一种新的递归注意网络,通过设计一个递归过程来建模事实描述和文章之间的迭代交互,更有效地完成了法律判决预测任务。
同时,为了进一步促进判决预测研究的深入应用,一些研究人员开始关注判决预测的实施过程,并探索了未来的方向。Zhong H X等人提出了一种基于强化学习的预测过程可视化模型,有效推进了法律判决预测的可解释性。Zhong H X等人深入研究了法律判决预测的子任务,利用子任务的依赖关系构建了有向无环图,提出了拓扑多任务的学习框架。Li J J等人提出了一种基于马尔可夫逻辑网络的求解方法,对法律因素的语义进行形式化描述和提取,然后建立、训练马尔可夫逻辑网络并进行预测,最后在司法离婚数据集上证明了该方法对预测结果具有可解释性。Liu Y H等人提出了一种基于文本挖掘的方法,通过分析普通大众的问题描述,为他们找到相似度较高的相关法律文书。Zhong H X等人总结了法律人工智能的研究历史、研究现状与未来的研究方向,并展示了一些在法律人工智能中有代表性的应用,深入分析现有工作的优缺点,探索未来可能的发展方向。
显然,现有研究大多针对法律判决预测的某一子任务开展,对完整的判决预测方法体系的研究相对较少。同时,现有方法大多以整篇的事实描述作为模型输入,而事实描述中通常包含较多对案件的判决结果影响较小的语句,这些语句会大大影响模型的特征学习,从而直接影响模型的判决预测效果。
3 判决预测流程
本文提出的基于法律裁判文书大数据的 法律判决预测流程主要由数据采集、数据预处理与判决结果预测三部分组成,具体流程如图2所示。
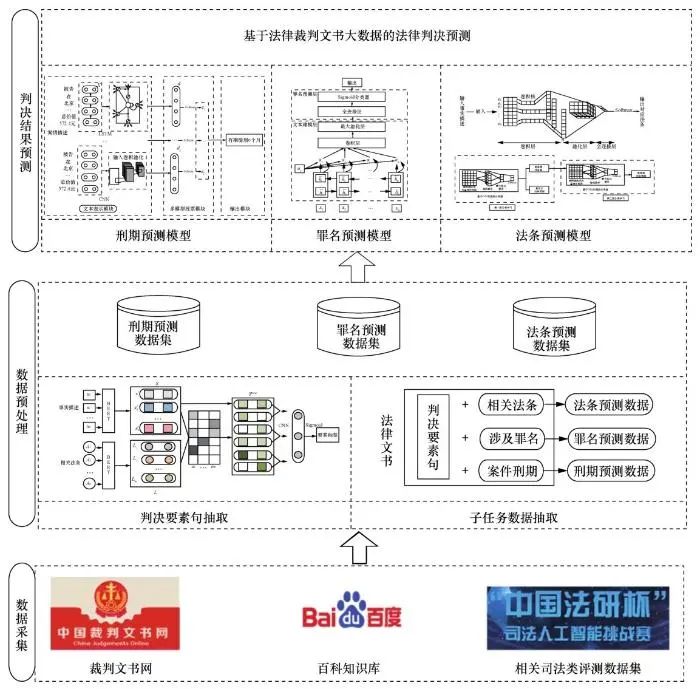
图2 法律判决预测流程
(1)数据采集
基 于法律裁判文书大数据的法律判决预测研究的实验数据分别由裁判文书网、百科知识库和相关司法类评测数据集三部分共同构成。本文在中国裁判文书网中爬取了海量不同种类案件的法律裁判文书,在百科知识库中获取了法条和司法解释等信息,在 2018“中国法研杯”司法人工智能挑战赛中获得了相应的评测数据集,同时,还基于相关的司法评测任务定义了实验数据的统一格式。本文使用的实验数据集共包含150 000篇刑法类法律文书和24 060篇离婚类法律文书。其中,刑法类法律文书涉及相关法条202条,相关罪名183种,案件刑期236类,离婚类法律文书涉及相关法条48条,判决结果2类。由于不同类型的文书有明显的差异,因此,实验过程中对刑法类案例分别进行了法条、罪名和刑期预测,对离婚类案例只采用判决预测模型进行了判决结果(“离”或“不离”)预测。
(2)数据预处理
将法律裁判文书等不同种类的数据规范化为司法评测的数据格式,抽取出数据中每个案件对应的事实描述、相关法条、涉及罪名和案件刑期等信息。再依照相关法条提取出不同种类案件事实描述中涉及的要素信息,如离婚类案件中的“婚后有子女”、劳动类案件中的“存在劳动关系”、借贷类案件中的“有书面还款承诺”等,这些要素信息是影响判决结果的关键信息,也是法律判决预测模型的输入信息。本文基于判决要素抽取模型对案件事实描述中的要素句进行抽取,并将每个案件的要素信息分别与该案件的相关法条、涉及罪名和案件刑期组合,得到法律判决预测3个子任务的数据集。
(3)判决结果预测
本文利用预处理后的大规模数据集,基于深度学习方法分别构建了法条预测模型、罪名预测模型和刑期预测模型,并用3类模型分别对案件进行法条预测、罪名预测和刑期预测,最终得到案例的判决预测结果。
4 判决预测方法
首先,本文针对判决要素句长度差异明显会对判决要素抽取结果影响较大这一问题,采用基于Mask方法的判决要素抽取方法,提高了案例的判决要素句自动抽取效果。然后通过分析法条、罪名和刑期3个预测任务的特点,分别对3个任务设计了独立的预测模型,针对法条预测任务中存在大量易混淆法条的问题,提出了基于模型融合与分层学习的法条预测模型;针对罪名预测任务中不同罪名的词语语义差异性问题,结合相关法条后提出了基于法条与语义差异性的罪名预测模型;针对事实描述中的重要因素对刑期预测任务的影响,总结了相关的量刑属性,提出了基于刑期属性与多模型投票的刑期预测模型。最后对3种模型进行联合训练,实现了案件的判决预测。
4.1 基于事实描述的判决要素抽取
法律裁判文书主要由案件类型、事实描述和判决结果等部分组成。其中,事实描述是一个司法案件的核心,包含逻辑清晰的原被告关系、事情的起因经过、案件涉及的伤亡程度和损失金额等相对关键的信息,这些信息是判决预测的重要依据,一般被认为是案件的判决要素。以往传统的法律判决预测模型大多将整篇事实描述作为输入,这一做法存在严重的缺陷。一方面,案件的判决结果往往主要侧重于一些重要的信息,事实描述中大多数语句对案件判决结果的影响十分微小,模型中输入过多的次要信息往往会直接影响模型的预测结果;另一方面,法律判决中最重要的问题之一是公平,但在现实世界中,由于审判过程中存在性别或种族歧视,判决不公的案件时有发生。而深度学习方法可能从事实描述中学习到这种偏见,并给法律体系带来不公平。因此,本文根据不同案件各自的特点,为每种类型的案件设计了要素标签,并按照要素标签从事实描述中抽取要素句,将要素句作为法律判决预测模型的输入部分,具体流程如图3所示。利用判决要素句进行判决预测不仅可以有效保留事实描述中影响判决结果的关键信息,一定程度上为模型消除了法官偏见,保证了判决公平性,同时也为模型给出的判决结果提供了可解释性。
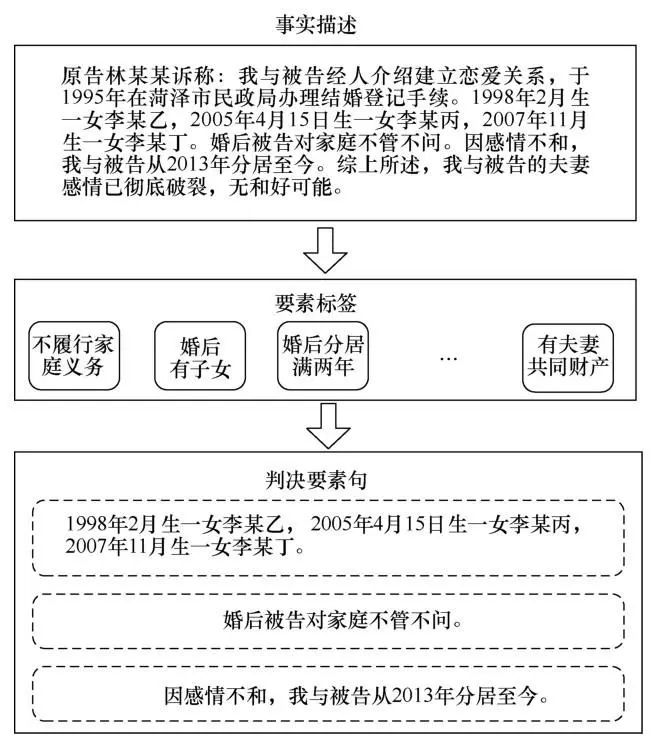
图3 判决要素句抽取流程
在判决要素抽取的模型设计过程中,本文采用文本分类的思想,提出了基于BERT(bidirectional encoder representations from transformers)模型的判决要素句抽取方法。然而,由于事实描述中的要素句长度差别较大,导致一些较短的要素句的句向量会出现很多0填充,这会明显影响最终的要素抽取结果。基于此,进一步在抽取模型中加入基于Mask方法的自注意力机制,以弱化输入向量的填充部分。
4.2 基于判决要素句的判决预测
案件的判决结果主要由案件的相关法条、涉及罪名与案件刑期三部分组成。人类法官给出的判决结果都是在综合了事实描述中的所有关键信息后得出的。因此,本文依照人类法官的判案思路,将法律判决预测任务分成法条预测、罪名预测与刑期预测3个子任务。以事实描述中抽取出的判决要素句为输入,基于深度学习的方法与文本分类的思想为法条预测、罪名预测和刑期预测任务分别构建独立的分类模型,具体过程如图4所示。
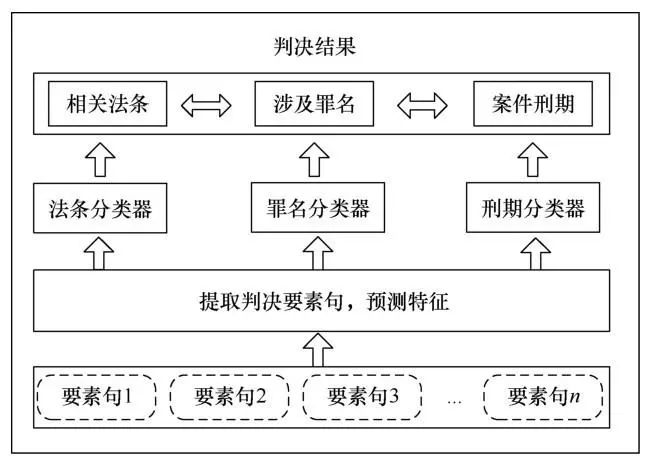
图4 法律判决预测模型
(1 )法条预测
法条是国家对人民规定的行为准则,它阐明了公民的权利和义务,设置了相应行为的法律后果,在一个法律案件的判决过程中,相关法条是判决的根本依据。本文分析大量真实案件与法条后发现,在案件的相关法条中存在一些较难区分的法条,如走私、贩卖、运输、制造毒品的法条内容与非法持有毒品的法条内容会出现较多相似的词汇,这些法条通常被称为易混淆法条,它们的语义相似度极高,区分难度较大,传统模型对易混淆法条的预测效果普遍较差。针对该问题,本文依据法条的相关司法解释,深入挖掘了判决要素句与相关法条之间的关系,提出了基于模型融合与分层学习的法条预测方法。该方法的具体流程如下。
① 根据已有法条预测的结果,针对刑法中涉及的183个法条,将其中的136个分为易区分法条,47个分为易混淆法条。
② 使用基于模型融合的法条分类器对案件的判决要素进行分类,预测出案件的法条编号。模型融合采用不同参数的卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN),结果输出使用Softmax分类器。
③ 结合①中划分的法条类别,判定输出的法条标签属于易区分法条还是易混淆法条。
④ 若法条属于易区分法条,则直接输出法条分类器的预测结果。
⑤ 若法条属于易混淆法条,则进一步将案件的判决要素输入相应的基于模型融合的易混淆法条分类器进行二次分类,并输出对应的分类结果。
具体的模型结构如图5所示。该方法融合了多种模型的特点,在一定程度上提升了易混淆法条的分类效果,有效提高了法条预测的准确性。
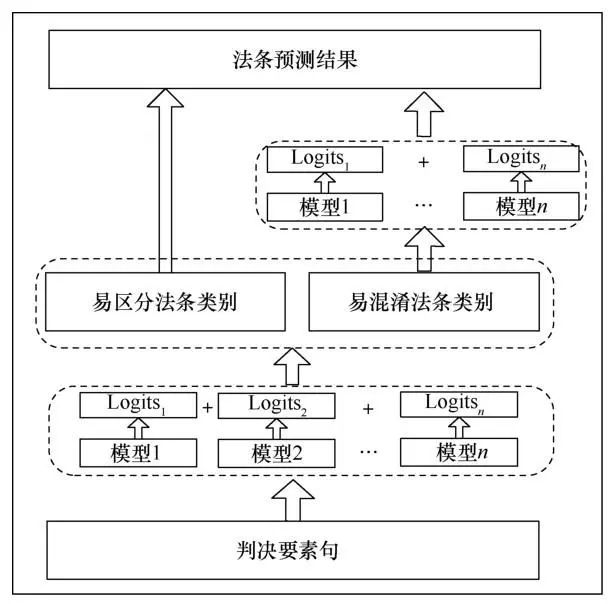
图5 基于模型融合与分层学习的法条预测模型
(2)罪名预测
罪名预测指通过分析案件的犯罪事实自动预测出被告的最终罪名。犯罪事实句中的各词语在区分不同罪名时,其语义重要性各不相同。例如对于盗窃罪与故意伤害罪,从犯罪目的来看,盗窃罪的犯罪目的为非法占有 他人财物,故意伤害罪的犯罪目的为故意伤害他人人身安全。此时,犯罪目的的语义是区分罪名的重点词。当两种罪名的犯罪目的都为非法占有他人财物时,从犯罪手段来看,两种罪名的犯罪手段分别为秘密窃取与使用暴力、胁迫的方式,此时的犯罪手段词成为区分罪名的关键词。而现有的方法大多忽略了这种语义性差异,从而对罪名预测的效果产生影响。同时,法条、司法解释等法律知识是人类法官定罪量刑的关键依据,引入外部法律知识对于罪名预测具有重要意义。针对这些问题,本文提出了基于法条与语义差异性的罪名预测方法,具体流程如下。
① 将判决要素句和相关法条分别输入BERT模型的编码器中,得到相应的句子级事实表示s和法条表示a。
② 使用法条注意力交互机制计算每一个判决要素句s与每一个法条a之间的法条相容性值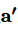 。
。
③ 使用语义自注意力交互机制计算每一个判决要素句s的语义重要性值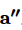 。
。
④ 利用得到的法条相容性值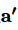 和语义重要性值
和语义重要性值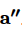 更新判决要素句s的向量表示。
更新判决要素句s的向量表示。
⑤ 通过Sigmoid分类器实现每个罪名的0/1二元分类。
具体实现过程如图6所示。实验证明,将该方法应用于罪名预测任务后,罪名预测的模型性能得到了有效提升。
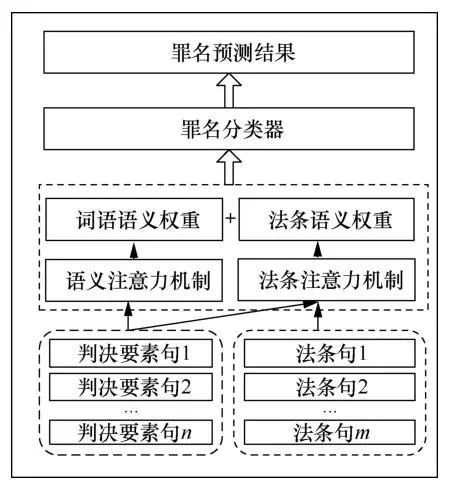
图6 基于法条与语义差异性的罪名预测模型
(3)刑期预测
刑期预测通常要求对判决要素句、相关法条与涉及罪名3个部分的信息进行综合考虑。本文分析了大量刑法类数据,将0~25年的刑期划分为20个刑期区间,根据数据中各种刑期的数据量分布,为不同刑期定义各自的预测偏差,在一定程度上缩小了预测结果与真实结果的偏差。同时,本文深入地分析了刑期预测任务,发现在事实描述中存在一些影响判决结果的重要因素,这些因素在法官的判决过程中具有十分重要的作用。针对该问题,本文通过分析海量案件的事实描述与量刑结果,提出了基于刑期属性与多模型投票的刑期预测方法,具体流程如下。
① 以每种案件的判决要素句标签为基础,结合具体法条、法律法规的内容为刑期预测设计量刑属性(大体可分为犯罪方式、受害者受伤程度、涉及财物规模、犯罪地点与其他属性5个类别),再根据不同的案件类型具体划分为多个案件专属小类别。
② 使用BERT模型分别对判决要素句与量刑属性进行编码,将判决要素句输入最大池化层得到其普通特征,通过注意力机制的方式将量刑属性融入判决要素句的向量表示中,并得到其属性特征。
③ 使用线性拼接的方式将普通特征与属性特征融合。
④ 将融合后的结果分别输入CNN、长短期记忆(long short-term memory, LSTM)网络和门控循环单元(gated recurrent unit,GRU)3种模型进行特征提取,再将3种模型的输出概率累加,最终取3种模型结果的平均值对应的类别作为预测的刑期类别,具体实现过程如图7所示。
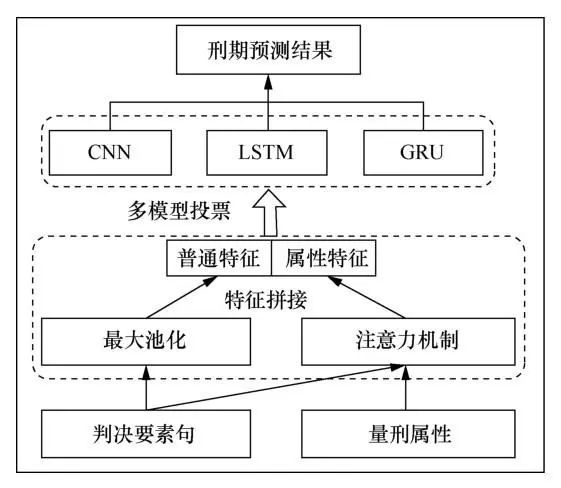
图7 基于刑期属性与多模型投票的刑期预测模型
4.3 实验结果与分析
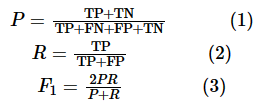
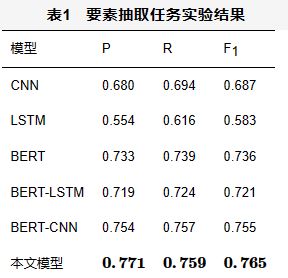
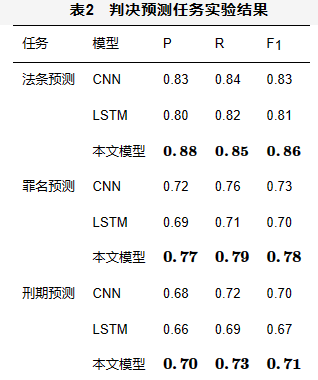
本文采用精确率P、召回率R和F1值这3个指标来评价针对要素抽取与判决预测任务提出的方法,精确率P、召回率R和F1值的计算式如式(1)、式(2)和式(3)所示,其中TP表示属于该类也被分为该类的样本数量;TN表示没有被分为该类且不属于该类的样本数量;FN表示没有被分到该类但属于该类的样本数量;FP表示被分到该类但不属于该类的样本数量。具体得出的实验结果见表1和表2。
(1)要素抽取
在要素抽取任务上,本文按照8:1:1的比例划分出训练集、验证集与测试集,并在5种基线模型上分别进行判决要素抽取实验,结果见表1。实验结果显示,CNN模型的结果优于LSTM模型,同样,在将BERT作为词嵌入方法的实验中,BERTCNN模型的结果明显优于所有基线模型。而本文基于Mask方法的判决要素抽取模型取得了最好的结果,与BERT-CNN模型相比,其在F1值上得到了0.01%的提升。
(2)判决预测
对于判决预测任务,本文将整理出的数据集按照8:1:1的比例划分出训练集、验证集与测试集,并选择CNN与LSTM模型作为基线模型,具体实验结果见表2。实验结果显示,CNN模型在3个判决预测任务中的结果都优于LSTM模型,本文提出的方法在3个任务中都得到了最好的结果,与两种基线模型相比都有明显的提升。
显然,本文提出的判决要素抽取方法和法条、罪名、刑期预测方法都有效地提升了判决预测的最终效果。
5 结束语
本文结合中国裁判文书网、百科知识库与相关司法类评测数据集构建了高质量的法律判决预测数据集,深入研究了基于法律裁判文书大数据的法律判决预测方法。首先基于BERT模型的判决要素句抽取模型对判决预测数据进行了预处理,然后分别提出了基于模型融合与分层学习的法条预测方法、基于法条与语义差异性的罪名预测方法和基于量刑属性与多模型投票的刑期预测方法,并对每种模型进行了实验验证。本文开展的研究为法律判决预测任务进行了有益的探索,为人工智能在智慧司法领域的应用提供了重要的参考价值。
作者简介
张虎(1979-),男,博士,山西大学计算机与信息技术学院副教授,主要研究方向为自然语言处理。
潘邦泽(1996-),男,山西大学计算机与信息技术学院硕士生,主要研究方向为自然语言处理。
谭红叶(1971-),女,博士,山西大学计算机与信息技术学院副教授,主要研究方向为自然语言处理。
李茹(1963-),女,博士,山西大学计算机与信息技术学院教授,主要研究方向为自然语言处理。
联系我们:
Tel:010-81055448
010-81055490
010-81055534
E-mail:bdr@bjxintong.com.cn
http://www.infocomm-journal.com/bdr
http://www.j-bigdataresearch.com.cn/
转载、合作:010-81055537
大数据期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的期刊,已成功入选中国科技核心期刊、中国计算机学会会刊、中国计算机学会推荐中文科技期刊,并被评为2018年、2019年国家哲学社会科学文献中心学术期刊数据库“综合性人文社会科学”学科最受欢迎期刊。

关注《大数据》期刊微信公众号,获取更多内容
原文链接:https://blog.csdn.net/weixin_45585364/article/details/121484318?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170018760316777224492052%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170018760316777224492052&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~times_rank-15-121484318-null-null.nonecase&utm_term=AI%E6%B3%95%E5%BE%8B%E5%92%A8%E8%AF%A2

