LLMs之Law:大语言模型纵向赋能场景—垂直行业场景应用之大模型法律行业的简介、主流LLMs(PowerLawGLM/ChatLaw)、经典应用之详细攻略
目录
T1、PowerLawGLM=基于GLM-130B+微调中文法律数据集+微调对齐+工程优化
2023年6月28日,清华大学(幂律智能联合智谱AI)法律大模型PowerLawGLM
第⼆步,微调对齐—与法律对话场景对⻬,具备法律场景的对话能⼒
T2、ChatLaw=基于Ziya-LLaMA-13B-v1(IDEA研究院的姜子牙)
《ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases》翻译与解读
法律行业大模型的简介
|
背景 |
2023年5月29日 据央视新闻报道,近日美国一名律师在一起诉讼案件中,引用了ChatGPT搜集的6个案例,而法官却发现那些信息全是胡编乱造。。这一事件揭示了人工智能在法律领域的潜在风险,包括误传错误信息。 |
||||
|
采用方案 |
采用通用大模型和专业法律模型对比
|
法律行业大模型主流LLMs
T1、PowerLawGLM=基于GLM-130B+微调中文法律数据集+微调对齐+工程优化
2023年6月28日,清华大学(幂律智能联合智谱AI)法律大模型PowerLawGLM
>> 聚焦于法律细分领域,针对中文法律场景的应用效果具有独特优势,具备丰富的法律知识和法律语言理解能力。
>> 基于GLM-130B
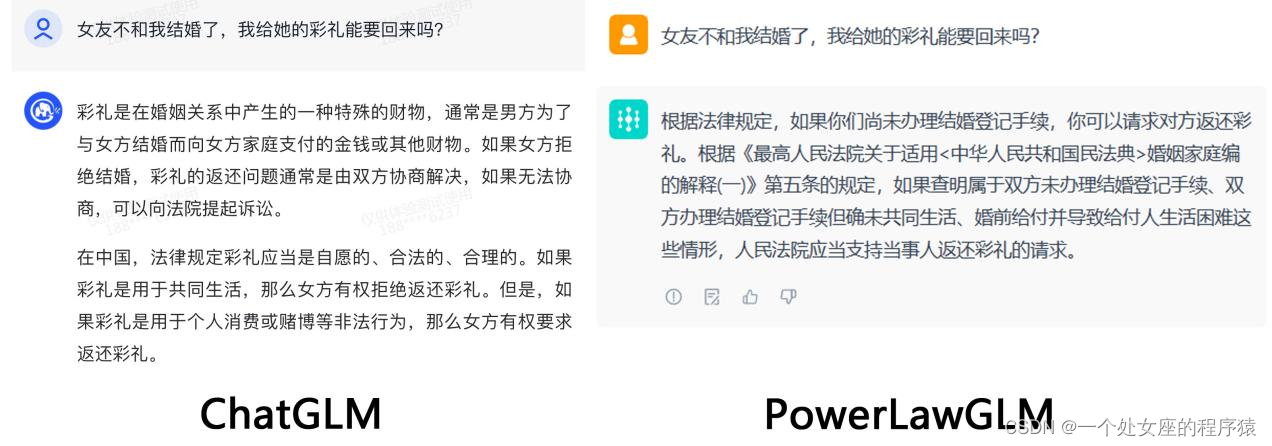
(1)、PowerLawGLM 示例:对比ChatGLM
(2)、PowerLawGLM 训练
第⼀步,收集专业领域语料—阅读⼤量法律⽂本
⾼质量法律⽂本数据(裁判⽂书、法律法规、法律知识问答等)模型增量训练。
第⼆步,微调对齐—与法律对话场景对⻬,具备法律场景的对话能⼒
法律领域对话数据进⾏监督微调。双⽅利⽤了近百万对⾼质量法律知识问题数据。
第三步,工程优化—优化保证输出结果质量和可靠性
通⽤型及场景特定型的⼯程化优化⽅案,提升法律问答的有法可依和引⽤法条内容的准确性。
(3)、评估PowerLawGLM:法律专业能力
法律问答

合同生成


T2、ChatLaw=基于Ziya-LLaMA-13B-v1(IDEA研究院的姜子牙)
2023年7月4日,北大法律大模型ChatLaw
ChatLaw-13B,此版本为学术demo版,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
ChatLaw-33B,此版本为学术demo版,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
论文地址:https://arxiv.org/pdf/2306.16092.pdf
GitHub地址:https://github.com/PKU-YuanGroup/ChatLaw
《ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases》翻译与解读
Abstract摘要
|
Large Language Models (LLMs) have shown the potential to revolutionize natural language processing tasks in various domains, sparking great interest in vertical-specific large models. However, unlike proprietary models such as BloombergGPT and FinGPT, which have leveraged their unique data accumulations to make strides in the finance domain, there hasn’t not many similar large language models in the Chinese legal domain to facilitate its digital transformation. In this paper, we propose an open-source legal large language model named Chat-Law. Due to the importance of data quality, we carefully designed a legal domain fine-tuning dataset. Additionally, to overcome the problem of model hallucinations in legal data screening during reference data retrieval, we introduce a method that combines vector database retrieval with keyword retrieval to effectively re-duce the inaccuracy of relying solely on vector database retrieval. Furthermore, we propose a self-attention method to enhance the ability of large models to overcome errors present in reference data, further optimizing the issue of model hallucinations at the model level and improving the problem-solving capabili-ties of large models. We also open-sourced our model and part of the data at https://github.com/PKU-YuanGroup/ChatLaw. |
大型语言模型(LLM)展现了在各个领域中革命性改变自然语言处理任务的潜力,引发了对垂直特定大型模型的极大兴趣。然而,与像BloombergGPT和FinGPT等专有模型不同,这些模型利用其独特的数据积累在金融领域取得了重大进展,而在中国法律领域并没有类似的大型语言模型来促进其数字化转型。 在本文中,我们提出了一个名为Chat-Law的开源法律大型语言模型。由于数据质量的重要性,我们精心设计了一个法律领域的微调数据集。此外,为了克服法律数据筛选中的模型幻觉问题,在参考数据检索期间,我们引入了一种将向量数据库检索与关键词检索相结合的方法,以有效减少仅依赖向量数据库检索的不准确性。此外,我们提出了一种自注意方法,以增强大型模型在克服参考数据中存在的错误方面的能力,从而进一步优化模型层面上的模型幻觉问题,并提高大型模型的问题解决能力。我们还在 https://github.com/PKU-YuanGroup/ChatLaw 上开源了我们的模型和部分数据。 |
1 Introduction引言
|
The continuous expansion and development of artificial intelligence have provided a fertile ground for the proliferation of large-scale language models. Models such as ChatGPT, GPT4 [5], LLaMA [7], Falcon [1], Vicuna [2], and ChatGLM [12] have demonstrated remarkable performance in various conventional tasks, unleashing tremendous potential for the field of law. However, it is evident that acquiring high-quality, relevant, and up-to-date data is a crucial factor in the development of large language models. Therefore, the development of effective and efficient open-source legal language models has become of paramount importance. In the realm of artificial intelligence, the development of large-scale models has permeated various domains such as healthcare, education, and finance: BloombergGPT [9], FinGPT [10], Huatuo [8], ChatMed [14], These models have demonstrated their utility and impact in tackling complex tasks and generating valuable insights. However, the field of law, with its inherent importance and demand for accuracy, stands as a domain that necessitates dedicated research and development of a specialized legal model. Law plays a pivotal role in shaping societies, governing human interactions, and upholding justice. Legal professionals rely on accurate and up-to-date information to make informed decisions, interpret laws, and provide legal counsel. The complexities of legal language, nuanced interpretations, and the ever-evolving nature of legislation present unique challenges that require tailored solutions. However, when it comes to legal issues, there is often a phenomenon of hallucination and nonsensical outputs, even with the most advanced model like GPT4. People tend to believe that fine-tuning a model with specific domain knowledge would yield satisfactory results. However, in reality, this is not the case with early legal LLM (LawGPT), as there are still many instances of hallucination and unreliable outputs. We initially recognized the need for a Chinese legal LLM. However, at the time, there were no commercially available Chinese models surpassing the scale of 13 billion parameters. Therefore, we built upon the foundation of OpenLLAMA, a commercially viable model, by expanding the Chinese vocabulary and incorporating training data from sources like MOSS. This allowed us to create a foundational Chinese language model. Subsequently, we incorporated legal-specific data to train our legal model——ChatLaw. |
人工智能的持续扩展和发展为大规模语言模型的增多提供了肥沃的土壤。ChatGPT、GPT4 [5]、LLaMA [7]、Falcon [1]、Vicuna [2]和ChatGLM [12]等模型在各种传统任务中展现了出色的性能,释放出了领域内的巨大潜力。然而,显而易见的是,获得高质量、相关和最新数据是发展大型语言模型的关键因素。因此,开发有效且高效的开源法律语言模型变得至关重要。 在人工智能领域,大型模型的发展已经渗透到医疗保健、教育和金融等各个领域:BloombergGPT [9]、FinGPT [10]、Huatuo [8]、ChatMed [14],这些模型展示了它们在解决复杂任务和产生有价值的见解方面的实用性和影响力。然而,法律领域以其固有的重要性和对准确性的需求,成为一个需要专门研究和开发专业法律模型的领域。 法律在塑造社会、管理人类互动和维护正义方面起着关键作用。法律专业人员依赖准确和最新的信息来做出明智决策、解释法律并提供法律咨询。法律语言的复杂性、微妙的解释和立法的不断变化为该领域提供了独特的挑战,需要量身定制的解决方案。 然而,就法律问题而言,即使在像GPT4这样的最先进模型中,常常会出现幻觉和荒谬的输出。人们倾向于认为使用特定领域知识对模型进行微调会产生令人满意的结果。然而,实际上,在早期法律LLM(LawGPT)中并非如此,因为仍然存在许多幻觉和不可靠的输出实例。 我们最初认识到需要一个中国法律LLM。然而,当时没有商业上可用的中国模型超过130亿的参数规模。因此,我们在OpenLLAMA的基础上进行了扩展,这是一个商业上可行的模型,通过扩展中文词汇表并将MOSS等来源的训练数据纳入模型,我们创建了一个基础的中文语言模型。随后,我们纳入了特定于法律的数据来训练我们的法律模型——ChatLaw。 |
|
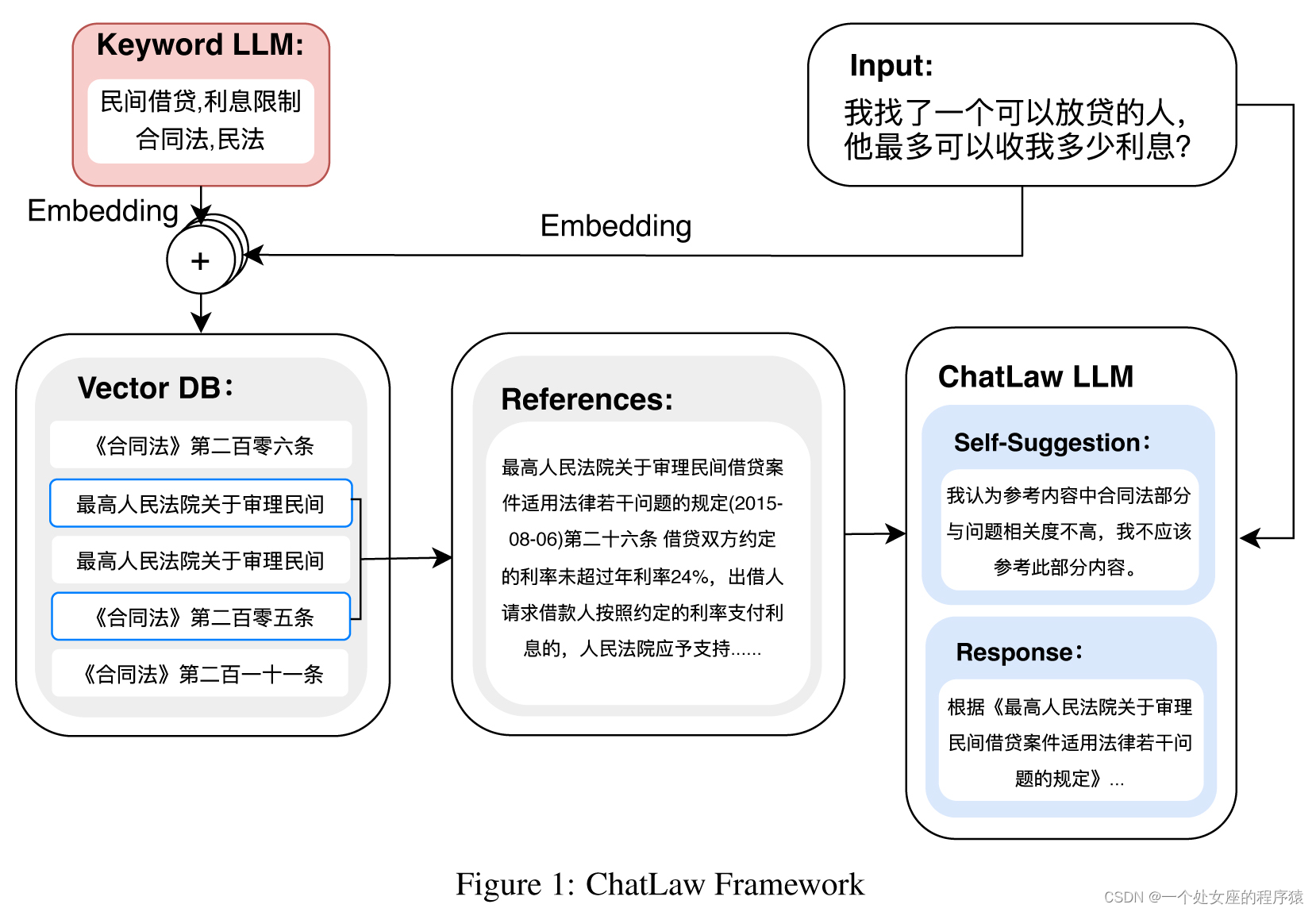
The key contributions of this paper are as follows: (1)、Effective Approach to Mitigate Hallucination: We propose an approach to address hallucination by enhancing the model’s training process and incorporating four modules during inference: "consult," "reference", "self-suggestion" and "response." By integrating vertical models and knowledge bases through the reference module, we inject domain-specific knowledge into the model and leverage accurate information from the knowledge base, reducing the occurrence of hallucinations. (2)、Legal Feature Word Extraction Model based on LLM: We train a model that extracts legal feature words from users’ everyday language. This model identifies words with legal significance, enabling efficient identification and analysis of legal contexts within user input. (3)、Legal Text Similarity Calculation Model based on BERT: We train a model to measure the similarity between users’ everyday language and a dataset consisting of 930,000 relevant legal case texts. This enables the creation of a vector database for efficient retrieval of similar legal texts, facilitating further analysis and reference. (4)、Construction of a Chinese Legal Exam Testing Dataset: We curate a dataset specifically designed for testing legal domain knowledge in Chinese. Additionally, we design an ELO arena scoring mechanism to compare the performance of different models in legal multiple-choice questions. |
本文的主要贡献如下: (1)缓解幻觉的有效方法:我们提出了一种方法来解决幻觉问题,通过增强模型的训练过程并在推断期间引入四个模块:“咨询”、“参考”、“自我建议”和“回应”。通过参考模块将垂直模型和知识库整合,将领域特定的知识注入模型,并利用来自知识库的准确信息,减少幻觉的发生。 (2)基于LLM的法律特征词提取模型:我们训练了一个模型,从用户的日常语言中提取法律特征词。该模型识别具有法律意义的词语,使得能够有效地识别和分析用户输入中的法律背景。 (3)基于BERT的法律文本相似度计算模型:我们训练了一个模型,用于衡量用户日常语言与包含930,000个相关法律案例文本的数据集之间的相似性。这使得能够创建一个用于有效检索相似法律文本的向量数据库,从而促进进一步的分析和参考。 (4)构建中国法律考试测试数据集:我们精心策划了一个专门用于测试中文法律领域知识的数据集。此外,我们设计了一个ELO竞技场评分机制,以比较不同模型在法律多项选择问题中的表现。 |
|
Furthermore, we observed that a single general-purpose legal LLM may not perform optimally across all tasks in this domain. Therefore, we trained different models for various scenarios, such as multiple-choice questions, keyword extraction, and question-answering. To handle the selection and deployment of these models, we employed a big LLM as a controller using the methodology provided by HuggingGPT [6]. This controller model dynamically determines which specific model to invoke based on each user’s request, ensuring the most suitable model is utilized for the given task. |
此外,我们观察到,在该领域中,单一通用的法律LLM可能在该领域的所有任务中表现不佳。因此,我们为不同的场景训练了不同的模型,例如多项选择题、关键词提取和问题回答。为了处理这些模型的选择和部署,我们采用了一个大型LLM作为控制器,使用HuggingGPT [6]提供的方法。这个控制器模型根据每个用户的请求动态确定要调用哪个特定的模型,确保最适合给定任务的模型被使用。 |
5 Conclusions结论
|
In this paper, we proposed ChatLaw, a legal large language model(LLM) developed using legal domain knowledge. We propose a novel approach that combines LLM with vector knowledge databases, which significantly alleviates the hallucination problem commonly seen in LLM. Our stable model handling strategies enable the resolution of various legal domain problems. Additionally, we release a dataset for legal multiple-choice questions and design an ELO model ranking mechanism. However, our limitations arise due to the scale of the base model. Our performance in tasks such as logical reasoning and deduction is not optimal. Additionally, after incorporating a large amount of domain-specific data, further research is required to improve the generalization of ChatLaw for generic tasks. There are potential social risks on ChatLaw, and we advise users to make use of our method for proper purposes. |
在本文中,我们提出了ChatLaw,这是一个使用法律领域知识开发的法律大型语言模型(LLM)。我们提出了一种新颖的方法,将LLM与向量知识数据库相结合,显著减轻了LLM中常见的幻觉问题。我们的稳定模型处理策略使得能够解决各种法律领域问题。此外,我们还发布了一个用于法律多项选择题的数据集,并设计了一个ELO模型排名机制。 然而,由于基础模型的规模,我们的限制也随之产生。我们在逻辑推理和演绎等任务中的表现并不理想。此外,在纳入大量领域特定数据之后,需要进一步的研究来改善ChatLaw在通用任务中的泛化能力。ChatLaw存在潜在的社会风险,我们建议用户合理使用我们的方法。 |
法律行业大模型的经典应用
更新中……
原文链接:https://blog.csdn.net/qq_41185868/article/details/132012789?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170018760216800184155654%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170018760216800184155654&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~times_rank-4-132012789-null-null.nonecase&utm_term=AI%E6%B3%95%E5%BE%8B%E5%92%A8%E8%AF%A2

