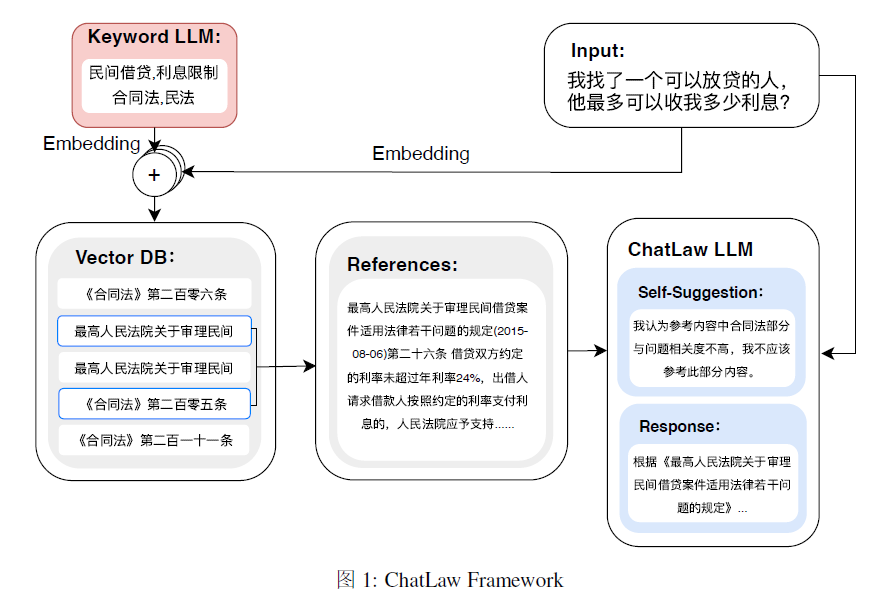
是一个chain式的垂类大模型,首先,KeyWord LLM提取关键词,通过这个关键词利用Law LLM,本质就是BERT去和法律条文计算相似度,拿到最高的法律条文送入ChatLaw LLM,这个模型是在ZIya-llama的基础上用lora微调的。
1.introduction
1.提出一种解决幻觉的方法,通过参考模块将垂直模型和知识库整合在一起,向模型中注入领域特定只是,并从知识库中获取准确的信息,减少幻觉的发生。
2.基于LLM的法律特征词提取模型,训练了一个模型,从用户日常语言中提取法律特征词,该模型能够识别具有法律意义上的词语,从而有效的识别和分析用户输入中的法律语境。
3.基于BERT的法律文本相似度计算模型,训练了一个模型,衡量用户日常语言与由93w份相关法律案例文本构建的数据集之间的相似度,这样可以构建一个向量数据库,以便高效检索相似的法律文本。
2.Dataset
收集大量原始法律数据:法律新闻,社交媒体内容以及法律行业论坛。

基于法律法规和司法解释的构建:将相关的法律法规和司法解释纳入数据集中。

爬取真实的法律咨询数据:利用现有的法律咨询数据集检索真实的法律咨询数据,使得数据集中包含了用户常遇到的真实法律情景和问题,为数据集增加了实用的法律案例。

构建律师考试的多项选择题:为律师考试专门设计了一套多项选择题,这些题目涵盖了各种法律主题。

数据被收集起来,清洗包括过滤掉短小和不连贯的回复,利用chatgpt api进行辅助建设,可以基于现有数据集生成补充数据。
3.training process
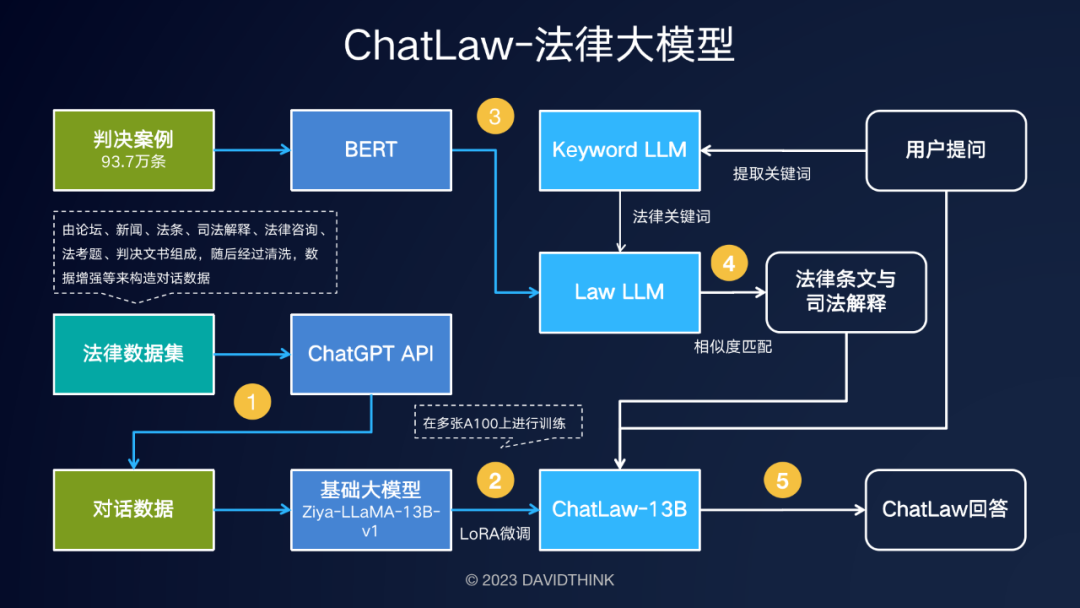
Keyword LLM是一种从用户提出的抽象咨询问题中提取关键词的语言模型,Law LLM提取可能涉及用户咨询的法律术语,ChatLaw LLM是最终的语言模型,向用户提供建议。
3.1 ChatLaw LLM
使用lora对Ziya-LLaMA-13B进行微调,A100+deepspeed。
3.2 Keyword LLM
使用预训练的BERT模型进行embedding,使用faiss方法计算余弦相似度,并提取与用户查询相关的前k条法规。目标是从用户查询中提取关键信息,并使用此信息的embedding来设计算法以提高匹配准确度。对一个LLM进行了微调,以提取用户查询中的关键词。

3.3 Law LLM
使用了一个包含937k个国家案例的数据集来训练一个BERT模型,以从用户查询中提取相应的法律条文和司法解释。
4.Experiments and analysis
收集了十年来的全国司法考试问题,制定了包含2000个问题及其标准答案的测试数据集。
引入与法律相关的问答和法规数据,在一定程度上可以提高模型在多项选择题上的表现。
在训练组中添加特定类型的任务明显提升了模型在这些任务上的表现。
法律多项选择题需要进行复杂的逻辑推理,因此具有更多参数的模型通常表现的更好。
原文链接:https://blog.csdn.net/u012193416/article/details/134042086?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170018760516800192295358%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170018760516800192295358&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~times_rank-2-134042086-null-null.nonecase&utm_term=AI%E6%B3%95%E5%BE%8B%E5%92%A8%E8%AF%A2

