大模型又「爆了」。
昨晚,一个法律大模型 ChatLaw 登上了知乎热搜榜榜首。热度最高时达到了 2000 万左右。
这个 ChatLaw 由北大团队发布,致力于提供普惠的法律服务。一方面当前全国执业律师不足,供给远远小于法律需求;另一方面普通人对法律知识和条文存在天然鸿沟,无法运用法律武器保护自己。
大语言模型最近的崛起正好为普通人以对话方式咨询法律相关问题提供了一个绝佳契机。

目前,ChatLaw 共有三个版本,分别如下:
-
ChatLaw-13B,为学术 demo 版,基于姜子牙 Ziya-LLaMA-13B-v1 训练而来,中文各项表现很好。但是,逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决;
-
ChatLaw-33B,也为学术 demo 版,基于 Anima-33B 训练而来,逻辑推理能力大幅提升。但是,由于 Anima 的中文语料过少,问答时常会出现英文数据;
-
ChatLaw-Text2Vec,使用 93w 条判决案例做成的数据集,基于 BERT 训练了一个相似度匹配模型,可以将用户提问信息和对应的法条相匹配。
根据官方演示,ChatLaw 支持用户上传文件、录音等法律材料,帮助他们归纳和分析,生成可视化导图、图表等。此外,ChatLaw 可以基于事实生成法律建议、法律文书。该项目在 GitHub 上的 Star 量达到了 1.1k。

官网地址:https://www.chatlaw.cloud/
论文地址:https://arxiv.org/pdf/2306.16092.pdf
GitHub 地址:https://github.com/PKU-YuanGroup/ChatLaw
目前,由于 ChatLaw 项目太过火爆,服务器暂时崩溃,算力已达上限。该团队正在修复,感兴趣的读者可以在 GitHub 上部署测试版模型。
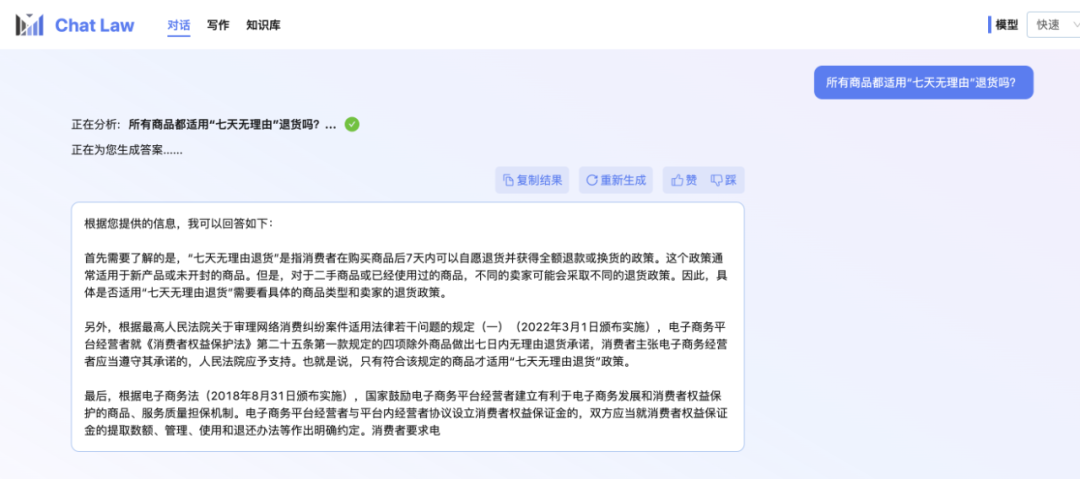
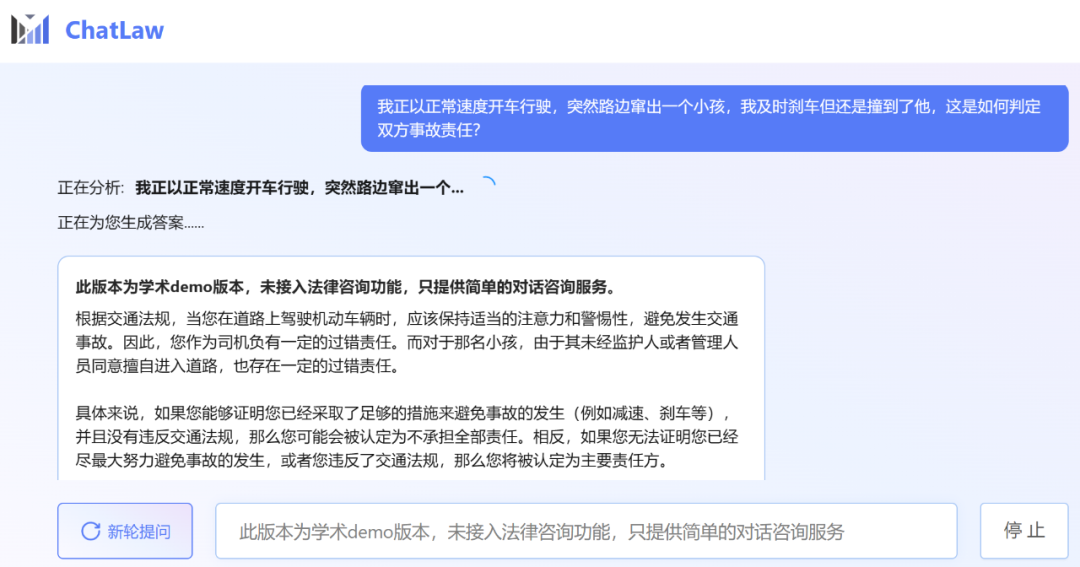
小编本人也还在内测排队中。所以这里先展示一个 ChatLaw 团队提供的官方对话示例,关于日常网购时可能会遇到的「七天无理由退货」问题。不得不说,ChatLaw 回答挺全的。
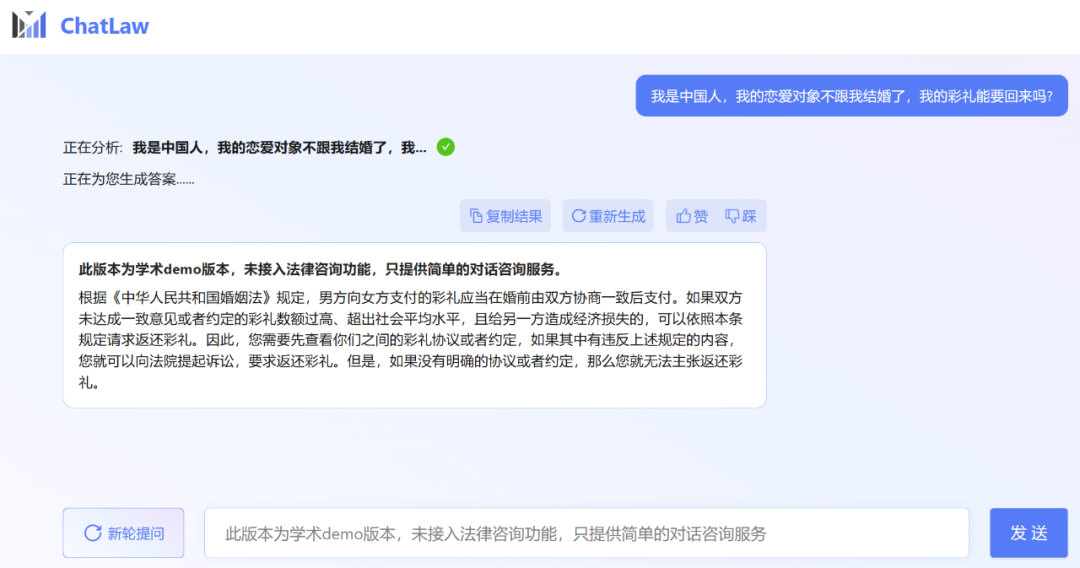
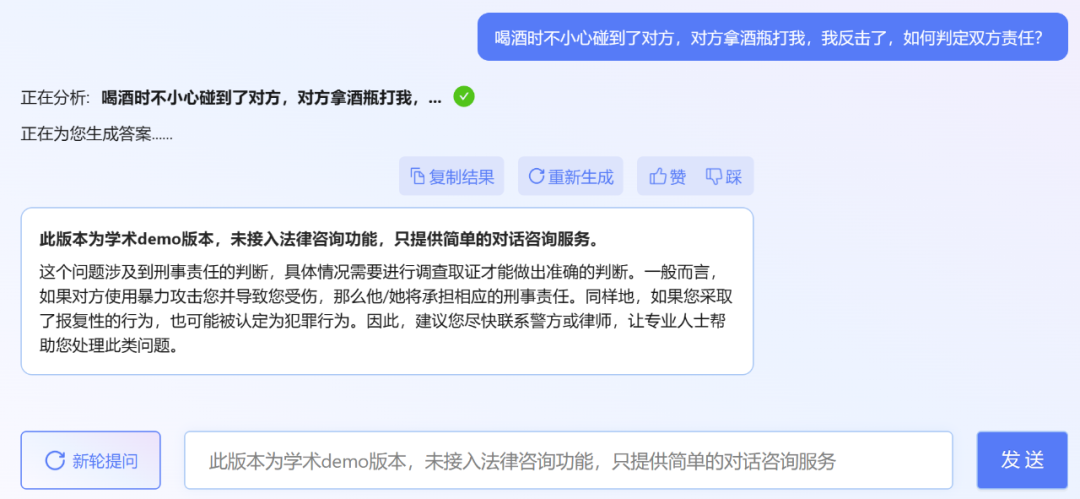
不过,小编发现,ChatLaw 的学术 demo 版本可以试用,遗憾的是没有接入法律咨询功能,只提供了简单的对话咨询服务。这里尝试问了几个问题。
其实最近发布法律大模型的不只有北大一家。上个月底,幂律智能联合智谱 AI 发布了千亿参数级法律垂直大模型 PowerLawGLM。据悉该模型针对中文法律场景的应用效果展现出了独特优势。

图源:幂律智能
ChatLaw 的数据来源、训练框架
首先是数据组成。ChatLaw 数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。同时,通过与北大国际法学院、行业知名律师事务所进行合作,ChatLaw 团队能够确保知识库能及时更新,同时保证数据的专业性和可靠性。下面我们看看具体示例。
基于法律法规和司法解释的构建示例:

抓取真实法律咨询数据示例:

律师考试多项选择题的建构示例:

然后是模型层面。为了训练 ChatLAW,研究团队在 Ziya-LLaMA-13B 的基础上使用低秩自适应 (Low-Rank Adaptation, LoRA) 对其进行了微调。此外,该研究还引入 self-suggestion 角色,来缓解模型产生幻觉问题。训练过程在多个 A100 GPU 上进行,并借助 deepspeed 进一步降低了训练成本。
如下图为 ChatLAW 架构图,该研究将法律数据注入模型,并对这些知识进行特殊处理和加强;与此同时,他们也在推理时引入多个模块,将通识模型、专业模型和知识库融为一体。
该研究还在推理中对模型进行了约束,这样才能确保模型生成正确的法律法规,尽可能减少模型幻觉。
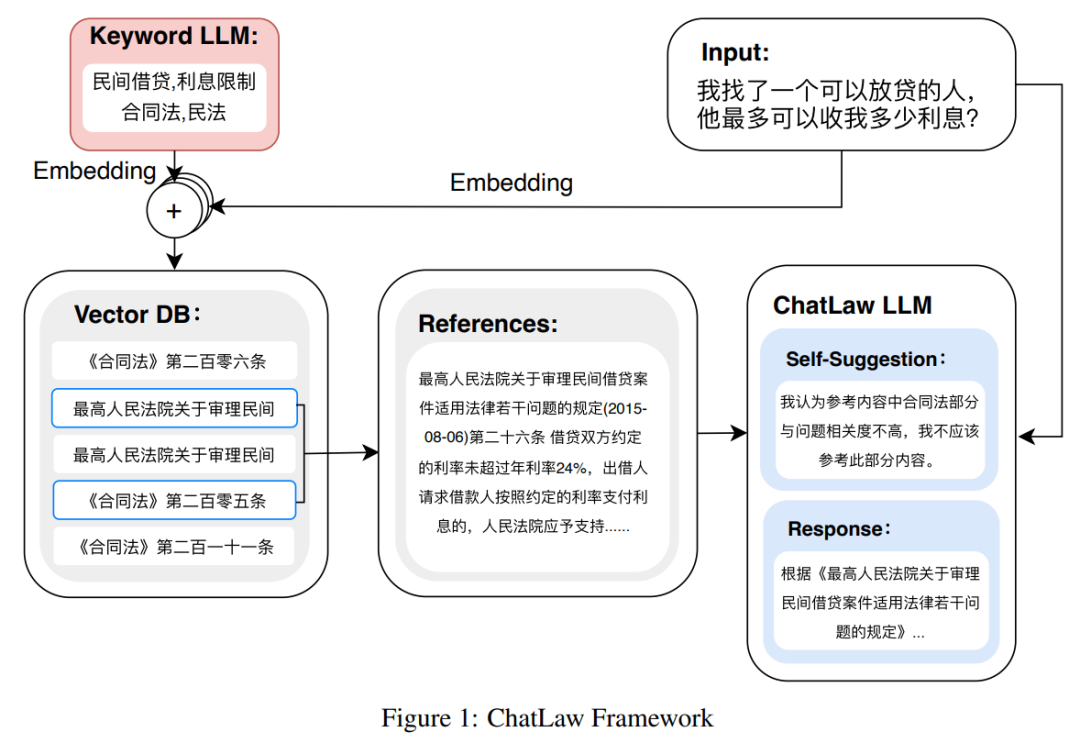
一开始研究团队尝试传统的软件开发方法,如检索时采用 MySQL 和 Elasticsearch,但结果不尽如人意。因而,该研究开始尝试预训练 BERT 模型来进行嵌入,然后使用 Faiss 等方法以计算余弦相似度,提取与用户查询相关的前 k 个法律法规。
当用户的问题模糊不清时,这种方法通常会产生次优的结果。因此,研究者从用户查询中提取关键信息,并利用该信息的向量嵌入设计算法,以提高匹配准确性。
由于大型模型在理解用户查询方面具有显著优势,该研究对 LLM 进行了微调,以便从用户查询中提取关键字。在获得多个关键字后,该研究采用算法 1 检索相关法律规定。

实验结果
该研究收集了十余年的国家司法考试题目,整理出了一个包含 2000 个问题及其标准答案的测试数据集,用以衡量模型处理法律选择题的能力。
然而,研究发现各个模型的准确率普遍偏低。在这种情况下,仅对准确率进行比较并无多大意义。因此,该研究借鉴英雄联盟的 ELO 匹配机制,做了一个模型对抗的 ELO 机制,以便更有效地评估各模型处理法律选择题的能力。以下分别是 ELO 分数和胜率图:
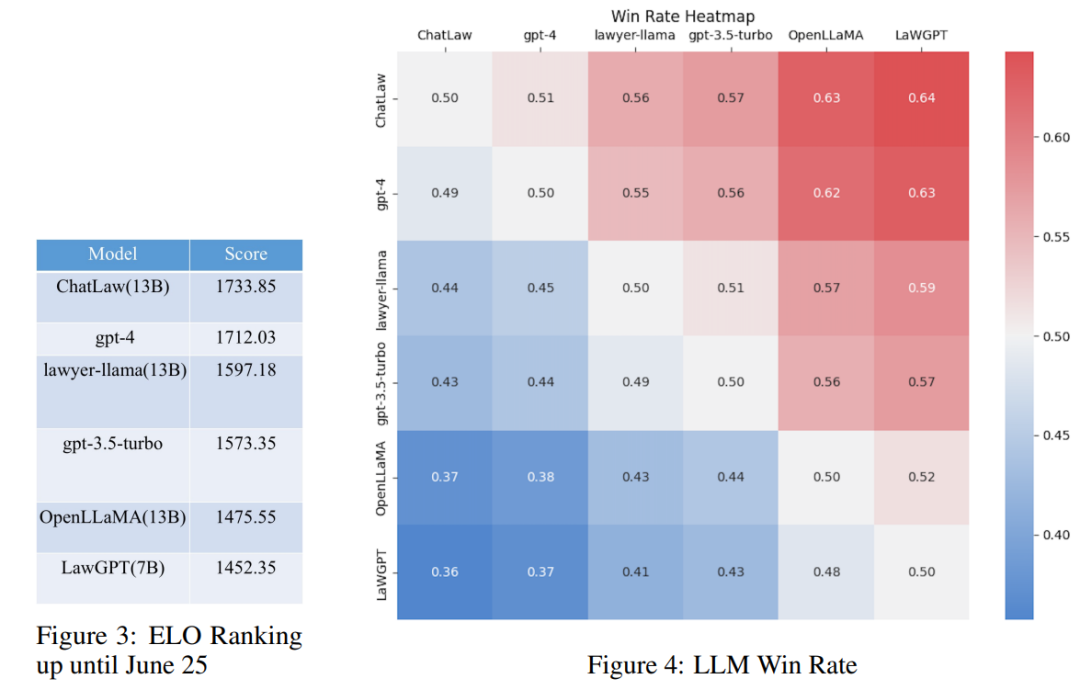
通过对上述实验结果的分析,我们可以得出以下观察结果
(1)引入与法律相关的问答和法规条文的数据,可以在一定程度上提高模型在选择题上的表现;
(2)加入特定类型任务的数据进行训练,模型在该类任务上的表现会明显提升。例如,ChatLaw 模型优于 GPT-4 的原因是文中使用了大量的选择题作为训练数据;
(3)法律选择题需要进行复杂的逻辑推理,因此,参数量更大的模型通常表现更优。
参考知乎链接:
https://www.zhihu.com/question/610072848
其他参考链接:
https://mp.weixin.qq.com/s/bXAFALFY6GQkL30j1sYCEQ
— 完 —
ChatGPT中文网站
可以在国内同ChatGPT直接进行对话,支持GPT4.0 和 AI绘图,简直太方便了,今天新注册的直接送提问次数 !
http://ai.cxyquan.com/ (复制到浏览器打开)

原文链接:https://blog.csdn.net/itcodexy/article/details/131606990?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170018760516800192295358%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170018760516800192295358&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~times_rank-16-131606990-null-null.nonecase&utm_term=AI%E6%B3%95%E5%BE%8B%E5%92%A8%E8%AF%A2

